Enable natural language prompting for SAM with CLIP embeddings.
Say Anything
Say Anything: Enable Natural Language Prompting for SAM with CLIP Embeddings
Segment Anything Model (SAM) has revolutionized image segmentation by enabling zero-shot generalization across diverse visual tasks. However, its original prompt-based interface relies on points, boxes, or masks, limiting intuitive human-computer interaction. The integration of CLIP (Contrastive Language-Image Pretraining) embeddings with SAM bridges this gap by allowing natural language prompts.
How It Works
This enhanced approach combines two powerful AI architectures:
- CLIP's semantic understanding converts text prompts into meaningful visual embeddings
- SAM's segmentation capability uses these embeddings to identify relevant image regions
Key Benefits
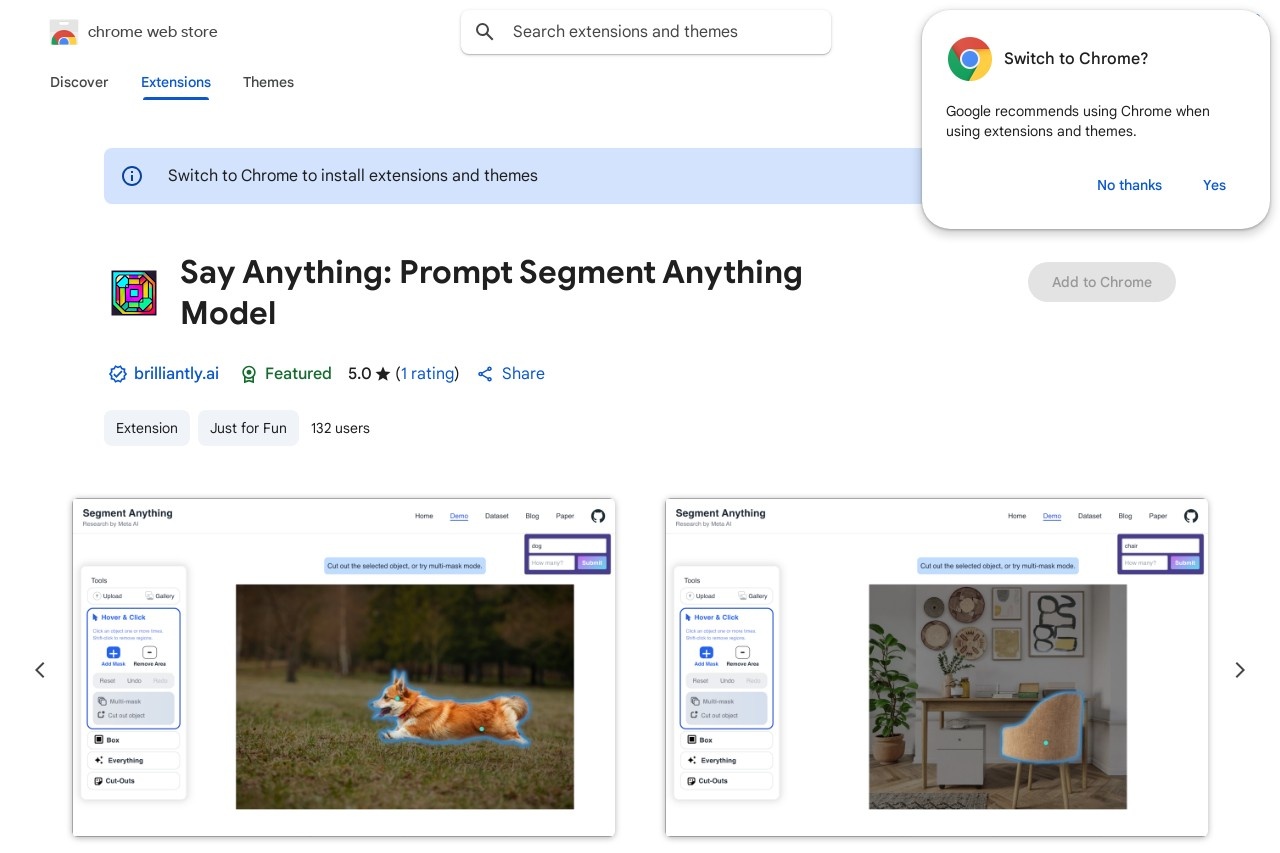
- Intuitive interaction: Users can describe target objects in plain English (e.g., "the red car" or "dog's tail")
- Precision enhancement: Language prompts provide semantic context beyond spatial cues
- Workflow efficiency: Reduces need for manual annotation while maintaining accuracy
Implementation Overview
The system processes natural language inputs through CLIP's text encoder to generate embedding vectors. These vectors then guide SAM's attention mechanisms during the segmentation process. The alignment between CLIP's multimodal space and SAM's visual understanding enables accurate region selection based on semantic meaning rather than just geometric cues.
Potential Applications
- Content creation tools for precise asset extraction
- Medical imaging with descriptive anatomy references
- Robotic vision systems responding to verbal commands
- Accessibility tools for visually impaired users
This advancement represents a significant step toward more natural human-AI collaboration in computer vision tasks, combining the strengths of large language models with specialized visual processing systems.